Improving Accuracy in Speech-to-Text Models

Siri, Alexa, Cortana, and Google Assistant are prominent examples of technologies built on sophisticated automatic speech recognition (ASR) systems. This technology falls under the broader category of natural language processing (NLP), a significant field in computational linguistics.
Understanding how to assess speech recognition systems effectively is crucial for deriving valuable insights from audio content. This straightforward guide will show you the essentials of evaluating these models.
Understanding Speech Recognition and Its Significance
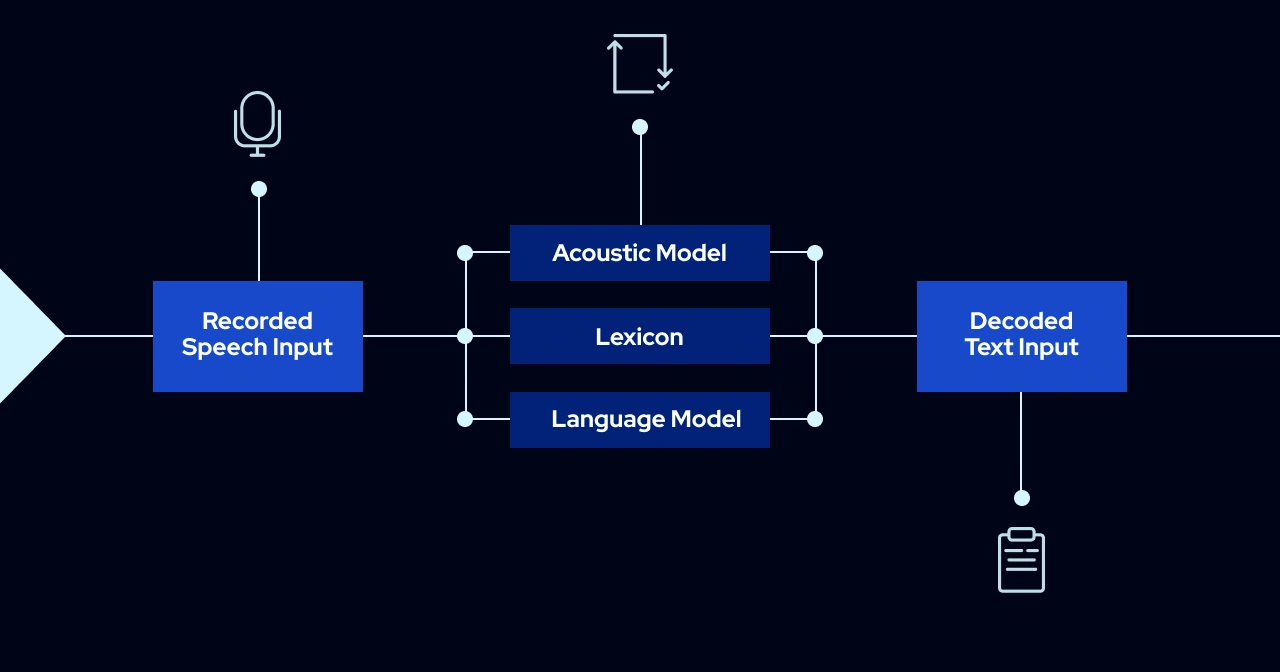
Speech recognition technology involves using statistical models to convert sequences of phonetic sounds—such as spoken words or speech waveforms—into readable text in human language. This process is facilitated by a trio of components within the ASR system: a Language Model, a Pronunciation Model (or Lexicon/Dictionary), and an Acoustic Model. Continuous training with diverse speech data from various speakers and an expanded vocabulary (Language Model) improves the precision of the transcription. This improvement is quantitatively assessed using the Word Error Rate (WER), where a highly accurate model is one with a WER of less than 10%.
The cornerstone of training an effective speech recognition model lies in the quality of the dataset, including the audio samples and the lexicon, as these elements are the foundation from which the models learn. Similarly, the clarity of the input audio directly influences the accuracy of the output. This principle mirrors human communication: unclear speech results in misunderstandings. For machines, poor audio quality leads to inaccurate transcriptions.
The power of speech recognition technology lies in its ability to unlock the vast potential of audio content. Audio files contain a wealth of information that, without transcription, remains difficult to navigate and search. Converting speech to text makes audio content accessible and searchable at a word level. Such functionality enables the creation of automatic subtitles for individuals with hearing impairments. It enhances the searchability of content archives beyond traditional metadata, facilitating easier access to large volumes of information. For example, journalists can locate specific footage for their stories based on keywords related to the event rather than relying on approximate dates, streamlining the research process.
How to Enhance Accuracy in Real-Time Transcription
Achieving high accuracy in real-time speech-to-text transcription is challenging, yet integrating the right APIs and optimizing your setup—ensuring clear audio capture, employing lossless audio formats, and utilizing techniques such as speaker diarization or separate audio channels—can significantly improve.
In real-time transcription, humorous but unhelpful errors can occur, such as nonsensical captions unrelated to the conversation. These errors, often resulting from the complexities of human speech, including accents, overlapping talk, and unfamiliar vocabulary, highlight the limitations of even the most sophisticated transcription systems.
Unlike its batch-processed counterpart, real-time transcription demands immediate, detailed attention to complex conversations, which can make it costly. However, advancements in AI technology are making real-time transcription not only more accurate but also increasingly affordable.
Here are key methods to improve the accuracy of your real-time speech-to-text transcriptions:
Ensure Clear Audio Quality
Clear audio is paramount for accurate transcription. This involves minimizing background noise and ensuring each speaker is audible and recorded in a high-quality format. Ideally, each participant would use their own wired microphone in a quiet environment. While achieving perfect audio clarity can be challenging outside controlled studio settings, it remains a critical factor for transcription accuracy.
Implement Speaker Diarization
Speaker diarization segments audio streams by speaker, aiding in accurately identifying and transcribing each participant's speech. Although it doesn't directly improve word error rates, it enhances overall transcription context and clarity, making it easier to understand who said what.
Capture Audio in Separate Channels
Capturing each speaker's audio in separate channels can greatly improve transcription quality by providing clear, individual audio feeds for each participant, effectively serving as a more defined form of speaker diarization.
Utilize Lossless Audio Formats
Using lossless audio formats like FLAC or WAV ensures the original audio quality is preserved, avoiding the quality degradation that comes with compressed formats. This is crucial for maintaining the integrity of the audio data for transcription.
Incorporate Custom Vocabulary
Adapting the transcription model to recognize industry-specific terminology or custom vocabulary can significantly enhance accuracy by ensuring that unique or specialized words are correctly identified and transcribed.
Add Custom Words
Integrating out-of-vocabulary (OOV) words into the speech-to-text engine's lexicon can reduce errors by allowing the system to recognize and correctly transcribe specialized terms.
Boost Keywords
Highlighting domain-specific phrases or keywords for the ASR model can improve its attention to these terms, enhancing the accuracy of transcriptions in specialized contexts.
Adapt the Language Model
Further adaptation of the language model to align with the expected utterances can be beneficial for scenarios where custom vocabulary and keyword boosting are insufficient. This process requires a comprehensive text corpus reflective of the language used in the target domain.
Acoustic Model Adaptation
Though rarely needed and costly, adapting the acoustic model to match better the speech patterns of specific user groups, such as children, can be the final step in optimizing transcription accuracy for niche applications.
These strategies, when combined, can significantly enhance the accuracy of real-time speech-to-text transcriptions, making them more reliable and useful across various applications.
How Voice-to-Text is Changing Our Lives and Industries
The future of voice-to-text technology in everyday life and across various industries holds remarkable promise, influenced by ongoing developments and future innovations. Here are some potential advancements and uses:
Effortless Multilingual Conversations: This technology is set to eliminate language barriers, enabling instant, real-time conversations across different languages. People will be able to speak in their native tongue while the system instantly translates, making global communication effortless.
Enhanced Healthcare Documentation: In healthcare, voice-to-text technology will transform how patient records are documented. Medical professionals will be able to dictate clinical notes and patient information accurately and swiftly, leading to improved patient care and efficiency.
AI-Enhanced Content Production: With AI enhancements, voice-to-text technology will become a vital tool for content creation. Authors, journalists, and creators will leverage voice dictation to draft articles, stories, and content more creatively and productively.
Streamlined Automated Customer Service: Voice-to-text systems will revolutionize customer service in call centers by handling inquiries with greater accuracy and efficiency, thanks to advanced natural language processing and machine learning. This will lead to shorter wait times and more precise answers.
Instant Transcription for Live Events: The technology will offer real-time transcription services for live events such as speeches, conferences, and lectures, making these gatherings more inclusive and accessible to a wider audience, including individuals with hearing disabilities.
Final Thoughts
In summary, voice-to-text technology is set to significantly impact our daily lives and industries, promising to improve communication, efficiency, and accessibility. As it evolves, this technology will streamline tasks, enhance interactions, and break down barriers, ushering in a new era of innovation and productivity. Embracing these advancements will be crucial for leveraging the full benefits of voice-to-text technology, paving the way for a more connected and efficient future.



